In the previous part, we have discussed Pose-Controllable Talking Face Generation, its challenges, and the general solution. In this part, we explain detailly the state-of-the-art solution for the mentioned task.
Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation (PC-AVS).
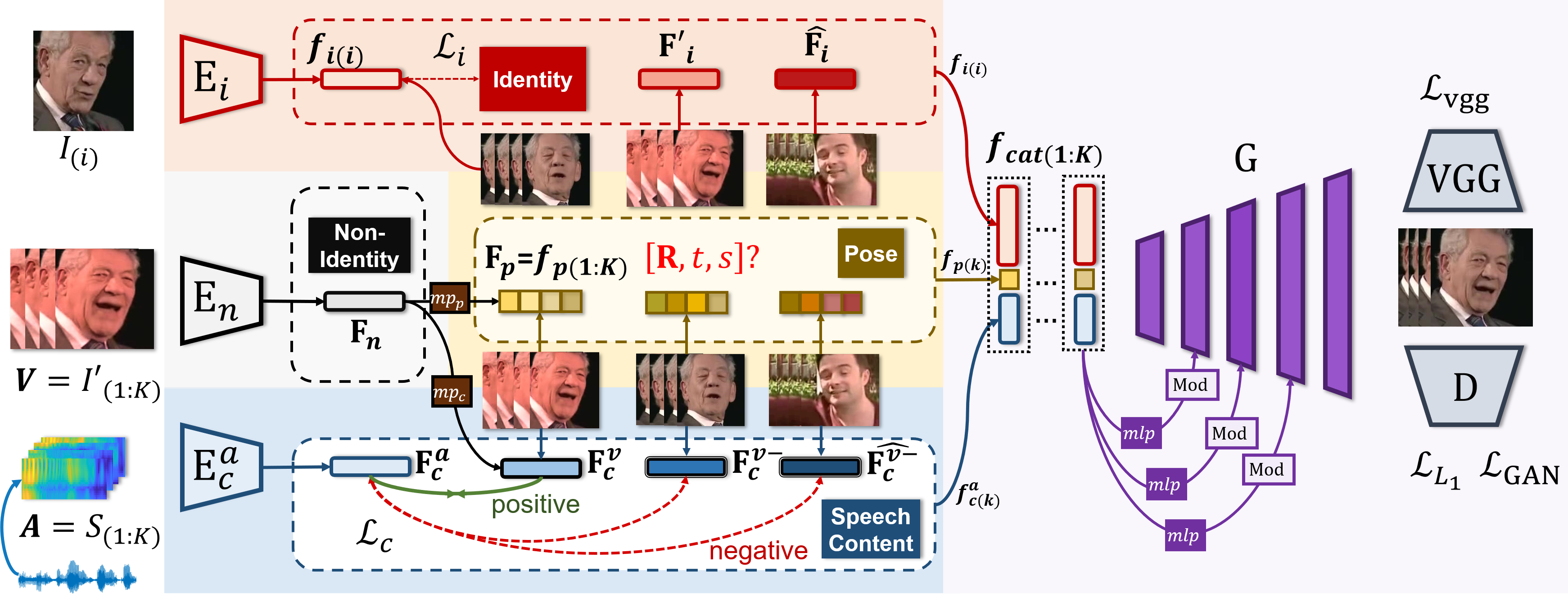
The detailed architecture of PC-AVS is shown in Figure 3. The below sections describe the ideas behind those changes:
- Pretraining to help the training phase.
- Identity and non-identity space.
- Speech Content Space and Pose Code.
- Generator.
Pretraining to help training phase
To create the input for the generator, we need identity space, pose code, and speech content space. But raw encoder may not work very well, so they pre-train first before learning to reconstruct the target frame. Specifically,
- Identity encoder : pretrained with classification task.
- Non-identity encoder : pretrained with visual-driven task. In this work, the author modified the Face Alignment Network (FAN) model (which is proposed for 2D to 3D face alignment task).
- Visual encoder () and audio encoder: pretrained with contrastive loss .
Identity and non-identity space
For identity space, the authors follow the common practice, they use a pretrained model in classification task to get this space. For non-identity space, the authors augment the pose source then forward it into a non-identity encoder. The data augmentation step is the key idea to produce non-identity space. In the reconstruction training phase, they need to use the first frame of the pose source video as an identity input image. Hence, they need to transform the pose source such that they do not look like the identity frame. So they use the idea that if they augment the pose video frames enough to make the difference. After encoding, the output latent space will contain only non-identity information. The authors in [1] chose augment methods to destroy major aspects (image texture and facial information) which 1 additional augmentation. Through empirical results, the authors show that without data augmentation, the model fails to learn pose.
Unlike identity space, which is only responsible for identity information, non-identity space is leveraged to learn both pose code and speech content space.
Speech Content Space and Pose Code
Because non-identity space contains information about speech content space and pose space. They use FC layers to split the information for each space.
Speech Content Space
The first FC layers will produce visual information . With the audio information encoded by as the input, the model is able to learn to sync the audio and visual. The sync space is speech content space. Later, they use only to represent speech content space for reconstruction training.
- To sync the audio and visual, they use a contrastive learning method. The only positive sample is where sync with (timely aligned). Other negative samples can be drawn from different videos or time shifts from the same source. After that, they transform the task into a classification task with negative log-likelihood loss. Their target is to max the cosine score of and .
- The speech content module is pretrained on video and audio encoding pose task first with a contrastive loss before finetuning in reconstruction task.
Pose Code
The second FC layers will produce a -dim pose code to express 3D head pose information. Our pose space is the proxy between the Ground Truth pose source and the generated frame.
Generator
After we have got 3 separated spaces:
- Speech content space .
- Pose code .
- Identity .
At frame , we concatenate them and use modulated convolution to generate the target frame. Modulated convolution is chosen because it has been proven to be effective in image-to-image translation [2]. Besides, they cannot apply the generator that leverages skip connection because of the model's structure (the pose information is latent space so skip connection may restrict the possibility of altering poses).
References
[1] H. Zhou, Y. Sun, W. Wu, C. C. Loy, X. Wang, and Z. Liu, "Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation", arXiv:2104.11116 [cs, eess], Apr. 2021, Accessed: Sep. 13, 2021. Paper
[2] T. Park, A. A. Efros, R. Zhang, and J.-Y. Zhu, "Contrastive Learning for Unpaired Image-to-Image Translation", arXiv:2007.15651 [cs], Aug. 2020, Accessed: Sep. 17, 2021. Paper